Data Storage
Data StorageAnalogy
Storing data on a computer is a lot like storing things in a warehouse. If you keep track of where you put things well enough, it shouldn't matter how much stuff you have stored.
Imagine an empty warehouse. If you store something in it, it doesn't really matter if you keep track of it because it's easy to look for it again. If the warehouse were full, you better keep track of where you put your stuff or you'll have to look everywhere for it. In a warehouse, you would probably write down an isle number, a shelf number, and maybe a pallet number. This way, you don't look through all the things, just go directly to the right place.
Warehousing Techniques
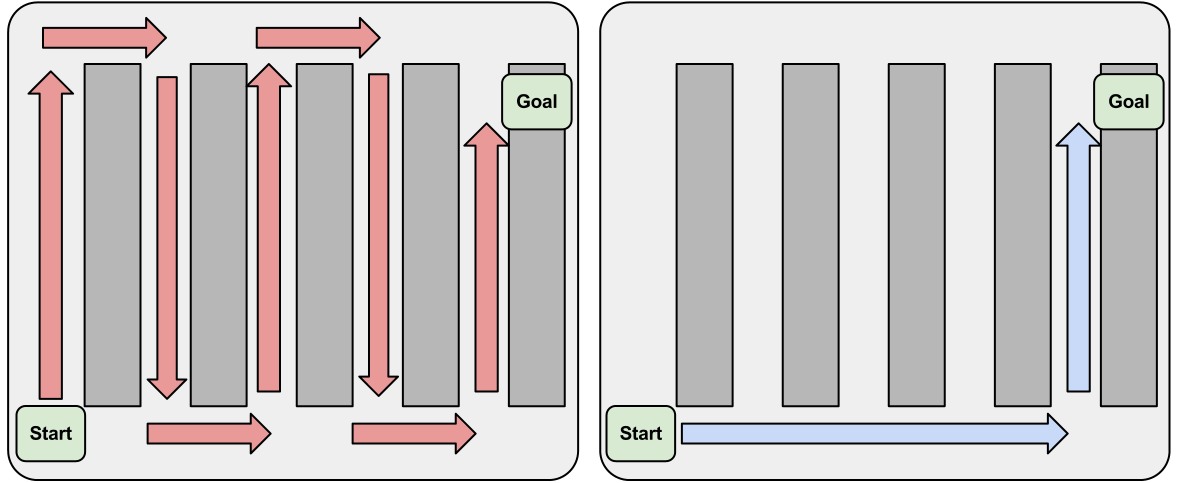
Unindexed Storage (left), Indexed Storage (right)
So, by keeping records of stuff as it comes in, you reduce the time it takes to look for it later. It is like what keeps your computer from getting slower when you add files to it. Your file system is the guy in the warehouse putting your files somewhere, and keeping track of where it should be so you can find it again quickly. This is how Google can search the entire internet in just milliseconds - by using a process called indexing. More data doesn't have to be slower. This is why it is important to understand how to store your data efficiently.
Linked Lists
A lot of the time, you have a specific order to things, but might want to be able to add or remove stuff at the beginning or in the middle. With an array, you would have shift the contents around to keep it in the right order. With a linked list, you just change a few pointers to change the order.
There are two main kinds of linked lists: queues and stacks. It's actually pretty easy to remember which is which. A queue is like the line at the grocery store (which in Britain, is actually called a queue), and a stack is like a stack of trays.
A queue is First In First Out (FIFO). Things are handled in the order they are receieved. This is extremely useful for things like buffers.
A stack is Last in First Out (LIFO). It's mostly useful for coming back to things if you get interrupted or retracing your steps.
The two are extremely similar in concept and implementation, but a queue is more common and more useful. A lot of programming languages and environments have pre-built versions of both these which are nice and reliable. Some examples of queue libraries: Python, C++ STL, and Arduino C. These queues are great because they dynamically expand at runtime, so they use only as much space as they need.
Using a Queue
Push: New things can be added to the end of the queue with a
queueName.push( newThing )
Pop: Once there are things waiting in the queue, you get the next one in line out by saying:
value = queueName.pop()
This both stores the value of the next one in line to the variable at the left, and removes it from the list, so be careful not to accidentally remove something before you're really done with it.
Peek: If you don't want to delete the next thing waiting, but still want to see what it is, you can take a peek at it with
value = queueName.peek()
Indexing
An index is like the index at the front or back of a book. You have a condensed table of things you might look for and a place to jump to. Indexes are great for speedy searches through data. The problem is that they require the data to be unique - otherwise you wouldn't know which place to jump to. You could try having a list of places to jump to, but at that point it gets complicated and you lose a lot fo the speed benefit that makes indexing so great. If you find yourself considering indexing to effectively organize your data, you might want to consider using a database instead.
If you want to keep it light or do it yourself, you may need to implement a hash table. A hash table is a way to look things up in constant time - which means it takes the same amount of time to find something no matter where it is.
Databases
In general, you will probably not be using a database on a robotic system. Many of the existing database applications would simply not work on an arduino. You could, however, put one on a raspberry pi.
It might be easiest to think of a database like a spreadsheet. Each column stores a specific kind of information. Unlike a spreadsheet, each row usually has a unique identifier, which can be used as the index. An index can be quickly found in the table. These are particularly useful for "merging" tables (the operation is called JOIN).
Databases are powerful tools for filtering complex data, and continue to be efficient on larger scales.
An example of potential use in a robot is that you could receive sensor readings with a raspberry pi, and store them in a database for analysis. Unless they data needs to be accessed during operation, it might just be easier to store the data to a file in a Comma Seperated Value sheet (CSV), which could then be opened in a spreadsheet program.